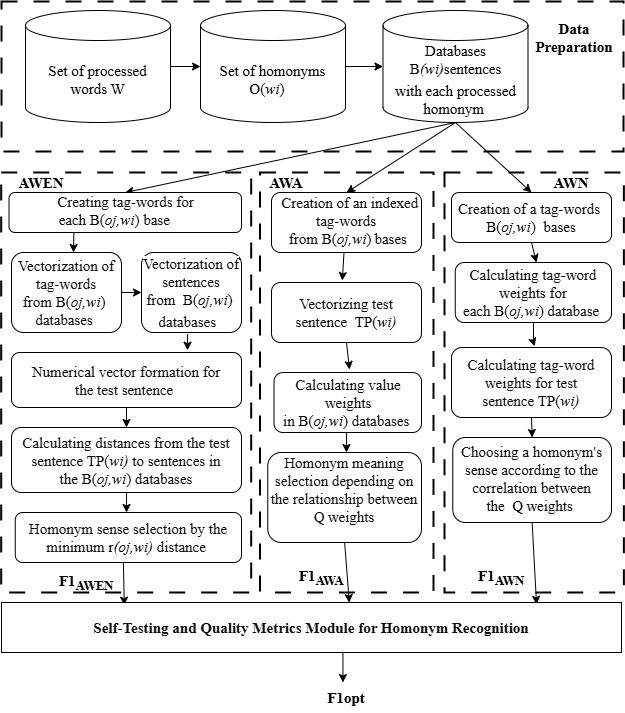
Актуальность исследования обусловлена острой нехваткой текстовых и аудиоданных для чеченского языка, что делает невозможным применение стандартных нейросетевых подходов к снятию лексической неоднозначности в системах синтеза речи. Разработана параметрическая модель и три алгоритма (AWEN на основе евклидова расстояния, AWA на основе взвешенного среднего и AWN на основе взвешенного нормализованного расстояния) для разрешения омонимии, отличающиеся использованием позиционного взвешивания контекстных слов без опоры на предобученные многоязычные трансформеры, обеспечивающие высокую точность при объеме обучающих предложений всего несколько сотен на один омоним и позволяющие интегрировать модуль распознавания в синтезатор речи с достижением F1-меры 0,78 для метода AWN.
Разработанное программное обеспечение и экспериментальные данные были созданы в рамках Года единства народов России, проводимого в Российской Федерации, что подчеркивает вклад в сохранение и развитие языкового многообразия народов страны.
Авторский коллектив отдела прикладной семиотики Академии наук Чеченской Республики, сектора искусственного интеллекта Комплексного института РАН имени Х. Ибрагимова, Санкт-Петербургского института информатики и автоматизации РАН (СПИИРАН, СПБ ФИЦ РАН), а также Школы бизнеса Университета Никосии (Кипр) успешно реализует данное междисциплинарное инициативное исследование.
Статья опубликована в международном рецензируемом журнале Big Data and Cognitive Computing. Журнал индексируется в базе Scopus (квартиль Q1), что подтверждает высокий уровень представленных результатов.
Izrailova, E.; Ronzhin, A.; Umarkhadzhiev, S.; Astemirov, A.; Figurek, A.; Sultanov, Z. Context-Oriented Method for Resolving Lexical Ambiguities in Speech Synthesis for a Low-Resource Language. Big Data Cogn. Comput. 2026, 10, 181. https://doi.org/10.3390/bdcc10060181